| Cooling Search 由四个核心模块组成 |
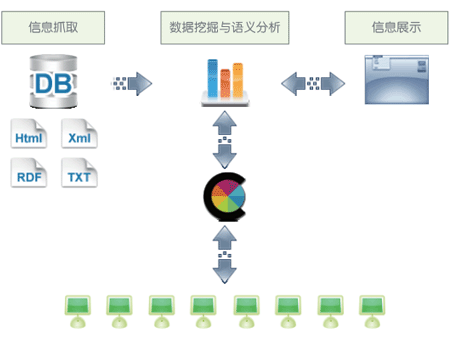
| Cooling 搜索引擎产品模型 |
 |
| |
| Spider |
| Spider 是 Cooling Search 的非结构与结构化数据的抓取与分析工具,更多时候它也被称为“网络爬虫”与“网络蜘蛛”。要建立一个高效的搜索引擎,最首要的任务是提高网络资源的抓取速度与效率,这样才能跟得上互联网信息增长的速度,Spider 在Cooling Search 中就承担着这么一个角色。 在非结构化数据方面,Spider 包含了完整的 HTTP/1.1,FTP,HTML/4,XML,RDF 的实现,能够识别与分析各类互联网文本。在结构化数据方面,Spider 能够支持对 Oracle,SQL Server,DB2,MySQL 等主流关系型数据的抓取与分析。 |
|
|
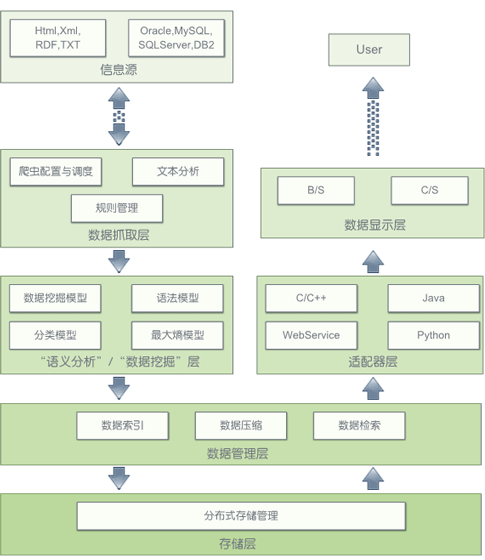
| Cooling 搜索引擎产品模型 |
 |
|
|
| Egg |
| Egg 是 Cooling Search 的索引平台,用来保存海量的非结构化数据,并提供基于关键字以及语义的高效检索。Egg 的核心理念是构建一套高效的索引机制,把原始的非结构化数据转化成可供检索的数据结构,并提升检索的效率。 |
| Schola |
Scholar 是 Cooling Search 的“语义分析”以及“数据挖掘”平台。
Scholar 通过对互联网信息的分析与挖掘,构建了一套完整的自然语言语料库以及基于统计观点的自然语言语法模型,为语义分析提供了可靠的基石。Scholar 目前还在不断地对互联网信息进行分析与挖掘,构建出各类有用的数据模型,力争为互联网应用带来更便捷更准确、更高效的搜索服务。
|
| Platform |
| Platform 为 Cooling Search 提供了分布式的存贮支持。Platform 架构了一个集群,将搜索引擎前端采集,分析并索引到的信息与模型,切分成数 据块,并将这些数据块的多个复本分发到集群中的不同节点之上。Platform 能够为 Cooling Search 提供更可靠,更高效以及更易于扩展的存贮结构。 |